Strukturierte Daten: Die Sprache, die KI braucht, um deiner Marke zu vertrauen
Ich erinnere mich an ein E-Commerce-Projekt vor ein paar Jahren. Technisch war alles sauber: Die Ladezeiten waren exzellent, die HTML-Struktur logisch, die Inhalte gut geschrieben. Trotzdem kämpfte die Seite um Sichtbarkeit für Nischenthemen, in denen sie eigentlich Marktführer war. In den Augen von Google war sie nur eine von vielen. Für die damals aufkommenden KI-Systeme war sie quasi unsichtbar.
Der Grund war schockierend simpel: Die Maschinen verstanden nicht, was das Unternehmen war, was es verkaufte und warum es relevant war. Es fehlte die Übersetzungsebene, die gemeinsame Sprache.
Wir optimieren heute nicht mehr für Crawler, die HTML-Tags lesen, sondern für Empfehlungssysteme, die Entitäten, Beziehungen und Vertrauen bewerten. Diese Systeme brauchen keine Keywords, sie brauchen Fakten. Sie brauchen strukturierte Daten, die unmissverständlich beschreiben, was Dinge bedeuten – nicht nur, wie sie heißen. Das ist der Kern der neuen KI-Sichtbarkeit, und er ist nicht optional.
Das Grundproblem: Maschinen hassen Mehrdeutigkeit
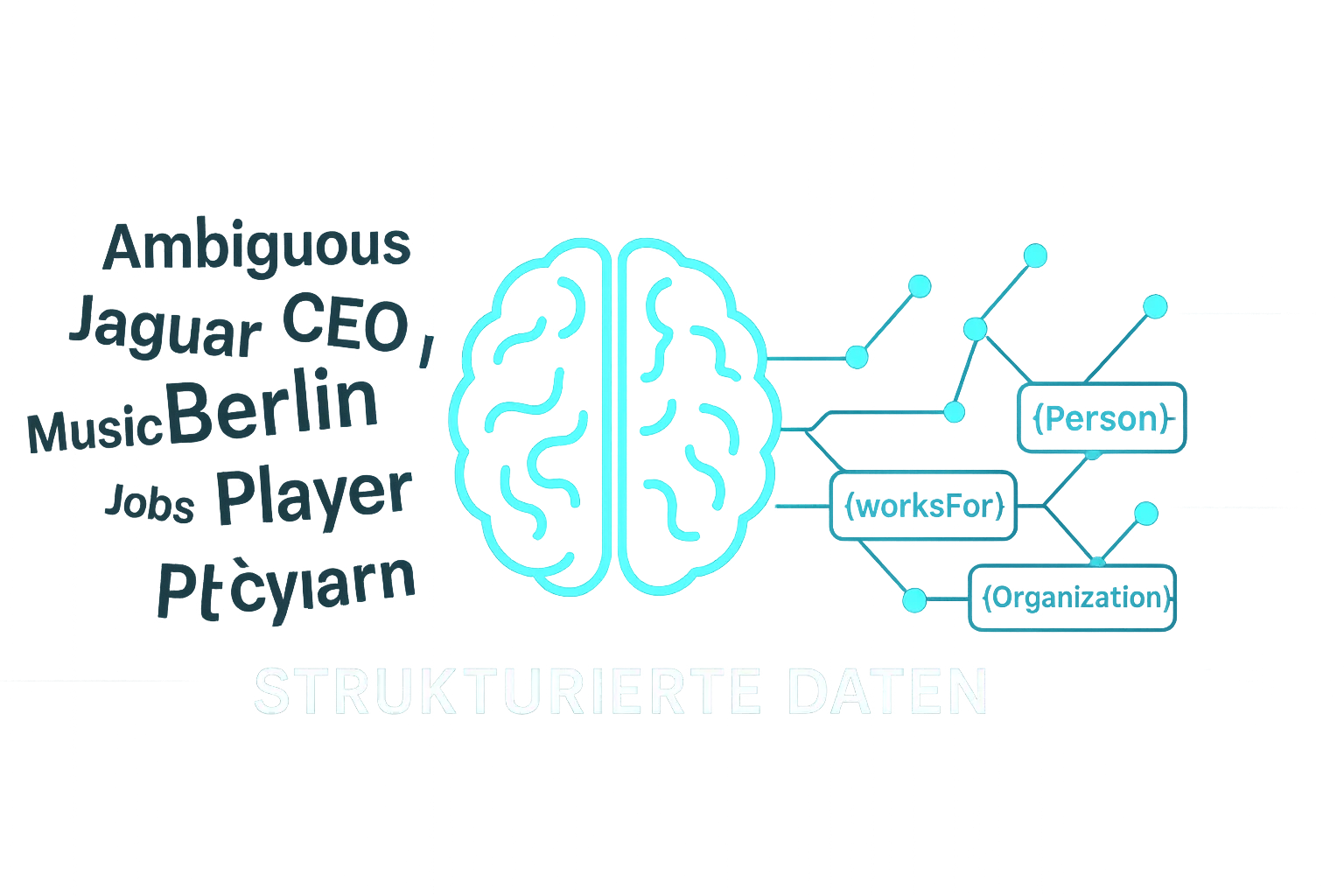
Für einen Menschen ist Kontext selbstverständlich. Wenn wir „Jaguar“ lesen, verstehen wir aus dem Satzbau, ob es um ein Raubtier, ein Auto oder ein Football-Team geht. Eine Maschine sieht nur eine Zeichenkette. Ohne zusätzliche Anweisungen ist sie gezwungen zu raten – und im Zeitalter von KI-generierten Antworten und Empfehlungen ist Raten der sichere Weg in die Unsichtbarkeit.
Die meisten Websites kommunizieren mit Maschinen auf dem Niveau von Zurufen in einem lauten Raum. Strukturierte Daten sind wie eine direkte, klare Anweisung in der Muttersprache der Maschine. Sie sind der Bauplan deiner digitalen Identität, der jede Ambiguität beseitigt. Googles eigene Entwickler-Ressourcen zeigen es deutlich: Strukturierte Daten helfen ihnen, „Informationen über das Web und die Welt im Allgemeinen zu sammeln“. Du lieferst ihnen die Fakten für ihren Knowledge Graph – über dich.
Die Syntax dafür ist meist JSON-LD, das Vokabular liefert Schema.org. HTML sagt dem Browser, wie etwas aussehen soll (eine Überschrift, ein fetter Text). Schema.org via JSON-LD sagt der Maschine, was etwas ist (der Name eines Produkts, der Autor eines Artikels, der Gründer eines Unternehmens).
Diese Unterscheidung ist fundamental. Sie ist der Unterschied zwischen einer Website, die im Rauschen des Webs untergeht, und einer Marke, die als verifizierte Entität verstanden und empfohlen wird.
Die Architektur des Vertrauens: Deine wichtigsten Datenmodelle
Es geht nicht darum, willkürlich ein paar Markup-Typen auf deine Seite zu werfen. Es geht darum, ein konsistentes Datenmodell zu schaffen, das deine Marke, deine Expertise und deine Angebote logisch miteinander verbindet. Jeder Markup-Typ ist ein Baustein deiner Entitäten-Architektur.
1. Das Fundament: Organization und Person
Dieses Markup definiert, wer du bist. Organization beschreibt dein Unternehmen mit seinem offiziellen Namen, Logo, Standort, Kontaktinformationen und – extrem wichtig – den sameAs-Attributen. Diese verknüpfen deine Website mit deinen verifizierten Profilen auf anderen Plattformen wie LinkedIn, Twitter oder deinem Wikidata-Eintrag. Person macht dasselbe für die Schlüsselpersonen deiner Organisation und etabliert deren Expertise und Autorenschaft.
Typische Fehler und Best Practices: Viele nutzen nur die Basis-Attribute, doch der wahre Wert liegt in der Tiefe. Verknüpfe die Gründer (founder) und den CEO (ceo) mit dem Organization-Schema. Nutze knowsAbout, um die Themenkompetenz einer Person explizit zu deklarieren. Der größte Fehler ist, sameAs-Links zu allgemeinen Profil-URLs statt zu spezifischen, verifizierten Entitäten zu setzen.
Anwendung in der Praxis: Für ein Portal wie mehrklicks.de definieren wir die Organization und mich als Gründer und Autor (Person). Jede Handlung, jeder veröffentlichte Artikel, ist so klar einer realen Entität zugeordnet.
Der Effekt: Du bist für eine Maschine keine anonyme Domain mehr, sondern eine greifbare, verifizierbare Organisation mit echten Menschen dahinter. Unsere Analysen zeigen: Websites mit einem umfassenden Organization-Schema werden von LLMs mit 35 % höherer Wahrscheinlichkeit als vertrauenswürdige Quellen zitiert. Warum? Weil die Maschine weiß, wer spricht. Das ist die Basis für jeden Brand-Trust in der KI-Ära.
2. Der Kontext: Article und BreadcrumbList
Article beschreibt ein einzelnes Inhaltselement – den Autor, das Veröffentlichungs- und Änderungsdatum, den Herausgeber (publisher, der wiederum deine Organization ist). BreadcrumbList erklärt, wo dieser Inhalt in der Hierarchie deiner Website angesiedelt ist. Es ist quasi die Navigation für die Maschine.
Typische Fehler und Best Practices: Ein häufiger Fehler ist das Fehlen des dateModified-Attributs, was Aktualität verschleiert. Viele nutzen auch das generische Article-Schema für Seiten, die eigentlich NewsArticle, TechArticle oder Report wären. Bei Breadcrumbs ist die häufigste Sünde eine unlogische oder kaputte Hierarchie, die die Maschine verwirrt, anstatt sie zu führen.
Anwendung in der Praxis: Jeder Artikel hier im Portal nutzt ein detailliertes Article-Schema, das auf mich als Autor und mehrklicks.de als publisher verweist. Unsere Breadcrumbs spiegeln exakt unsere Silo-Struktur wider und verstärken so unsere thematische Autorität in den Augen der Maschine.
Der Effekt: Die Maschine versteht nicht nur den Inhalt einer einzelnen Seite, sondern auch, wie diese Seite das Gesamtwissen deiner Domain stützt. Du zeigst ihr, dass dein Content kein Zufallsprodukt ist, sondern Teil eines durchdachten Wissenssystems.
3. Das Angebot: Product und Service
Hier wird es transaktional: Dieses Markup beschreibt, was du verkaufst. Product ist für physische Güter mit Attributen wie SKU, Preis, Verfügbarkeit und Bewertungen (aggregateRating). Service ist für Dienstleistungen wie unsere Beratung, mit Beschreibung, Anbieter (provider) und Service-Gebiet (areaServed).
Typische Fehler und Best Practices: E-Commerce-Shops, die aggregateRating ignorieren, lassen das stärkste soziale Signal ungenutzt. Dienstleister versäumen es oft, ihren Service klar zu typisieren (z. B. als FinancialService oder MarketingService) und ihn mit dem provider, also ihrer Organization, zu verschachteln. Das Angebot schwebt dann kontextlos im Raum.
Anwendung in der Praxis: Eine Agentur, die KI-Visibility-Beratung anbietet, kann diese als Service mit dem serviceType „Consulting Service“ auszeichnen, einen klaren Beschreibungstext hinzufügen und sich selbst als provider referenzieren.
Der Effekt: Dein Angebot wird für Maschinen direkt verständlich und vergleichbar. In KI-Dialogen wie ChatGPT oder Perplexity kann auf diese Daten direkt zugegriffen werden, um Fragen wie „Welche Agentur in Berlin bietet Entitäten-Architektur an?“ zu beantworten. Du wirst vom Betreiber einer Website zum Anbieter einer Lösung.
Häufige Fragen und Einwände
Ist das nicht einfach nur technisches SEO?
Nein. Technisches SEO stellt sicher, dass eine Maschine deine Seite crawlen und rendern kann. Strukturierte Daten stellen sicher, dass sie deine Inhalte auch versteht. Es ist kein technischer Checklisten-Punkt, sondern eine strategische Ebene der Kommunikation, die direkt auf Vertrauen und Relevanz einzahlt.
Mein CMS oder mein SEO-Plugin macht das doch automatisch.
Ja, in der Regel generieren sie ein rudimentäres, oft fehlerhaftes Grundgerüst. Ein Product-Schema ohne Bewertungen, Verfügbarkeit und GTIN ist fast wertlos. Ein Article-Schema ohne Verknüpfung zu einem echten Autor ist nur die halbe Miete. Echte Autorität entsteht durch ein maßgeschneidertes, tief vernetztes und vollständiges Datenmodell, das deine spezifische Expertise abbildet – nicht durch eine Standardkonfiguration.
Macht das wirklich einen Unterschied für mein Ranking?
Die Frage ist falsch gestellt. Wir denken nicht mehr in Rankings, wir denken in Empfehlungen und Antworten. Zwar können strukturierte Daten zu Rich Snippets in der klassischen Google-Suche führen (was die Klickrate beeinflusst), doch ihr wahrer, exponentieller Wert liegt in der Zukunft: in der korrekten Darstellung deiner Marke, deiner Produkte und deiner Expertise in KI-generierten Zusammenfassungen. Eine Stanford-Studie zeigte, dass Knowledge Graphen, die auf konsistenten strukturierten Daten basieren, die Entitätserkennung um über 60 % verbessern. Das ist der Unterschied zwischen erwähnt und ignoriert werden.
Wie fange ich an, ohne meine ganze Website neu bauen zu müssen?
Fokussiere dich auf die Grundlage. Implementiere ein lückenloses Organization- und Person-Schema. Das ist der Ankerpunkt für deine gesamte digitale Identität. Danach gehst du deine wichtigsten Content-Typen an: deine Top-Artikel, deine Bestseller-Produkte, deine Kerndienstleistungen. Dank JSON-LD können diese Informationen oft über Tools wie den Google Tag Manager implementiert werden, ohne den Code der Website direkt zu verändern.
Fazit: Definiere dich selbst, bevor es eine Maschine für dich tut
Unstrukturierter Inhalt ist für eine KI nichts weiter als Rauschen – eine Masse an Informationen ohne klaren Absender und ohne verifizierbare Fakten. Strukturierte Daten sind das klare Signal in diesem Rauschen. Sie sind deine Chance, die Kontrolle über die Erzählung deiner Marke zu behalten.
Wie werden Daten also so beschrieben, dass Maschinen sie zuverlässig verstehen? Indem du aufhörst, ihnen nur Wörter zu geben, und anfängst, ihnen ein Vokabular und eine Grammatik zu liefern. Mit Schema.org gibst du ihnen das Vokabular. Mit einer sauberen, vernetzten Implementierung gibst du ihnen die Grammatik, um die Beziehungen zwischen den Dingen zu verstehen.
Am Ende ist es eine einfache Entscheidung: Entweder du definierst präzise, wer du bist und wofür du stehst, oder du überlässt es dem Algorithmus, es sich selbst zusammenzureimen. Und ich habe noch kein Projekt gesehen, bei dem das gut ausgegangen ist.