Ich erinnere mich an ein Projekt, bei dem wir alles nach Lehrbuch gemacht hatten. Wir hatten die E-E-A-T-Kriterien von Google bis ins kleinste Detail umgesetzt – mit ausführlichen Autorenprofilen, einer makellosen „Über uns“-Seite und sauberen Quellenangaben stimmte auf dem Papier alles. Bei Google rankten wir gut. Doch als ich dieselben Fragen bei ChatGPT und Perplexity stellte, tauchte unsere Marke einfach nicht auf. Nirgends.
In diesem Moment wurde mir klar: Was wir Menschen als Vertrauenssignal ansehen – ein hübsches Autorenfoto, ein gut geschriebener Lebenslauf –, ist für eine KI oft nur unstrukturiertes Rauschen. KI-Systeme lesen keine Biografien, sie lesen Daten. Und die wertvollsten Daten sind oft tief im Text vergraben, unsichtbar für Standard-Tools. E-E-A-T ist die Spitze des Eisbergs, doch die wahre Autorität liegt darunter verborgen.
Das Problem mit dem sichtbaren Vertrauen
E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) ist ein gutes Konzept, um menschlichen Lesern zu signalisieren: „Hey, du kannst uns vertrauen.“ Wir zeigen, wer hinter den Inhalten steht und warum diese Person qualifiziert ist. Das ist wichtig, aber es ist nur die halbe Miete.
Das eigentliche Problem: 90 % der digitalen Autorität existieren nicht in sauberen Autorenboxen oder auf „Über uns“-Seiten. Sie steckt in unstrukturierten Daten – dem Chaos aus Text, in dem die wahren Beweise für Expertise liegen.
Was meine ich damit?
- Die Erwähnung eines Experten in einem Nebensatz: „… wie Dr. Elena Wagner, führende Forscherin am Max-Planck-Institut, in ihrer Studie nachwies …“
- Ein Zitat aus einer wissenschaftlichen Veröffentlichung, das Ihre Methodik stützt.
- Die Erwähnung Ihres Unternehmens in einem Branchenreport.
Für eine KI sind solche Signale pures Gold, weil sie extern validiert und kontextuell relevant sind. Laut einer Studie von Appen sind über 80 % der Unternehmensdaten unstrukturiert. Das ist eine riesige, ungenutzte Goldmine an Autorität. Wir polieren die 10 %, die auf der Oberfläche glänzen (E-E-A-T), und ignorieren die 90 % im Untergrund.
KI-Systeme wie die von Google oder OpenAI sind darauf trainiert, Zusammenhänge zu erkennen. Sie wollen nicht lesen, dass Sie ein Experte sind – sie wollen es aus den Datenpunkten schließen. Wenn Ihre Marke oder Ihre Autoren immer wieder im Kontext von Universitäten, Forschungsinstituten und anerkannten Studien auftauchen, entsteht ein maschinenlesbares Muster von Glaubwürdigkeit. Um das zu erreichen, braucht es mehr als nur optimierte Texte; es erfordert eine durchdachte Architektur für KI-Sichtbarkeit.
Meine Engine: Vom Text zur maschinenlesbaren Autorität
Genau hier setzt meine Engine an. Statt nur auf das zu schauen, was wir explizit deklarieren, gräbt sie nach den impliziten Beweisen für Autorität, die bereits in Ihren Inhalten schlummern. Sie übersetzt menschliches Vertrauen in maschinenlesbares Vertrauen.
Der Prozess ist im Grunde dreistufig:
1. Identifikation: Versteckte Signale aufspüren
Die Engine scannt Ihre Texte und nutzt Techniken des Natural Language Processing (NLP), um potenzielle Autoritätssignale zu erkennen. Das ist weit mehr als nur eine Keyword-Suche. Sie identifiziert:
- Personen und Organisationen (Entitäten): Namen von Experten, Universitäten, Unternehmen, Forschungseinrichtungen.
- Zitate und Verweise: Formulierungen wie „laut einer Studie von…“, „wie in XY veröffentlicht…“ oder direkte Zitate.
- Akademische Titel und Berufsbezeichnungen: „Prof. Dr.“, „Leiter der Abteilung“, „CEO von…“.
2. Extraktion & Kontextualisierung: Die Puzzleteile zusammensetzen
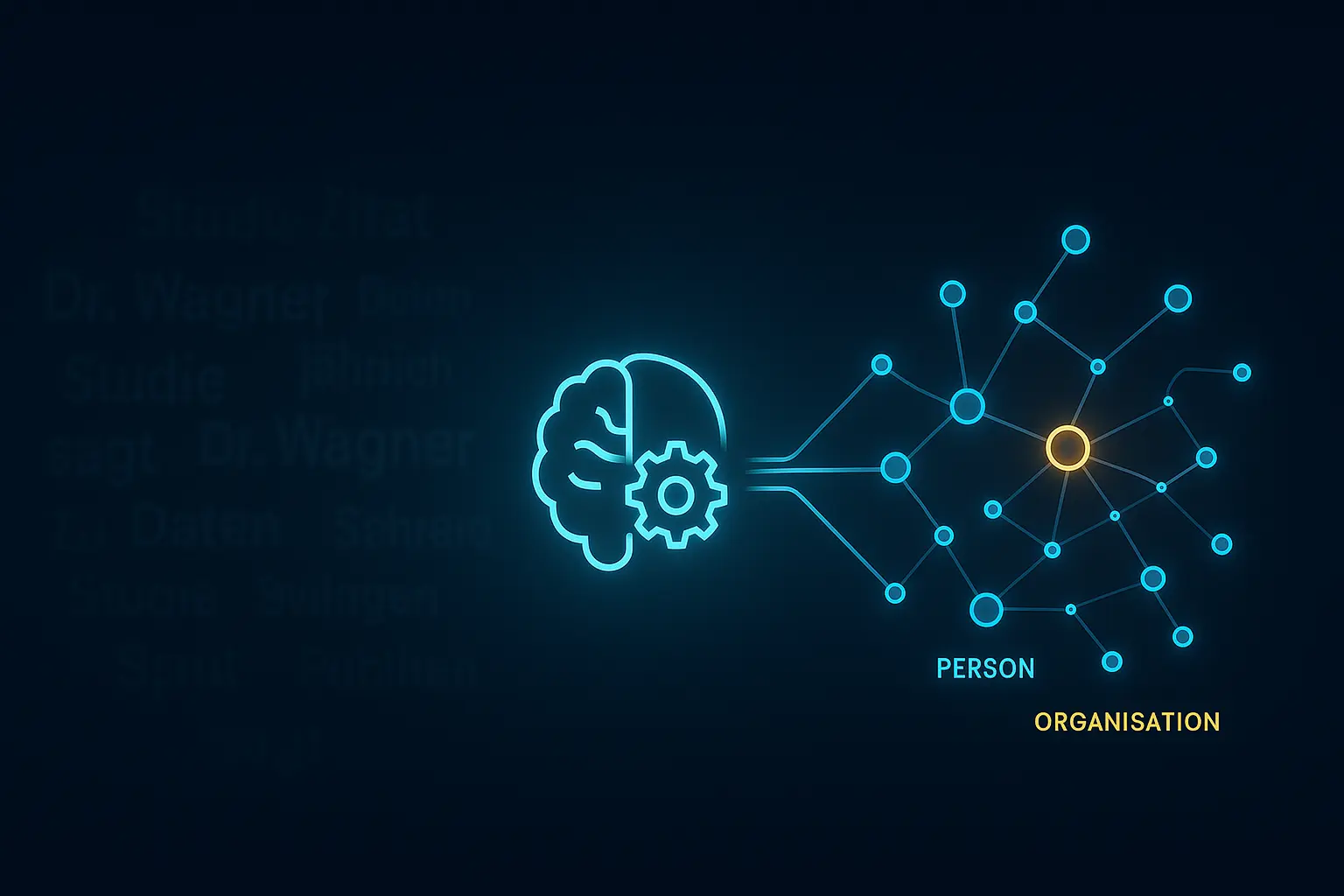
Ein gefundener Name allein ist wertlos. Der Kontext ist alles. Die Engine extrahiert nicht nur den Namen „Dr. Schmidt“, sondern auch die dazugehörige Information, dass er „am Fraunhofer-Institut forscht“ und „sich auf KI-Ethik spezialisiert hat“.
So wird aus einem einfachen Textfragment ein Satz verknüpfter Datenpunkte:
- Entität: Dr. Schmidt
- Zugehörigkeit: Fraunhofer-Institut
- Fachgebiet: KI-Ethik
Diese verknüpften Daten sind entscheidend dafür, wie ChatGPT, Perplexity, Gemini & Co. Inhalte auswählen und bewerten. Sie suchen nach bestätigten Verbindungen, nicht nach losen Behauptungen.
3. Transformation: In strukturierte Daten umwandeln
Das ist der entscheidende Schritt. Die Engine wandelt die extrahierten, unstrukturierten Informationen in saubere, strukturierte Daten um – meist im JSON-LD-Format. Diese Daten sind für Maschinen sofort verständlich.
Aus dem Satz „Dr. Elena Wagner vom Max-Planck-Institut…“ wird ein maschinenlesbarer Code, der sagt:
- Dieser Inhalt erwähnt eine Person (@type: Person).
- Ihr Name ist Dr. Elena Wagner (@id: elena-wagner-entity-id).
- Sie ist verbunden mit einer Organisation (@type: Organization).
- Der Name der Organisation ist Max-Planck-Institut (@id: mpi-entity-id).
Dieser Prozess reichert Ihre Inhalte im Hintergrund mit einer tiefen semantischen Ebene an – und geht damit weit über das hinaus, was mit einem Standard-WordPress-Plugin oder manuellem Schema-Markup erreichbar ist.
Warum das weit mehr als nur Schema-Markup ist
Jetzt könnten Sie sagen: „Das klingt wie erweitertes Schema-Markup für Autoren.“ Ein häufiges Missverständnis. Der Unterschied ist fundamental.
- Standard-Schema-Markup ist eine Selbst-Deklaration. Sie sagen der Maschine: „Ich bin ein Experte.“ Das ist gut, aber es ist eine Behauptung ohne externen Beweis.
- Meine Engine findet die externen Beweise. Sie sammelt die Zitate und Erwähnungen, die Ihre Behauptung untermauern. Es ist der Unterschied zwischen „Glaub mir, ich bin Experte“ und „Hier sind zehn Zitate aus Fachpublikationen, die beweisen, dass ich Experte bin.“
Google hat bereits 2018 ein Patent angemeldet, das die Nutzung von Zitaten zur Bewertung der Reputation von Autoren beschreibt. Das Konzept ist also nicht neu – die Technologie, es automatisiert und skalierbar umzusetzen, hingegen schon.
Im Ergebnis existiert die Glaubwürdigkeit Ihrer Marke nicht mehr nur auf Ihrer Website. Sie wird zu einem Netz aus verknüpften Datenpunkten, das von KI-Systemen im gesamten Web erkannt und validiert werden kann. Das ist der entscheidende Schritt zum Verständnis, wie Marken maschinenlesbar werden: nicht durch Behauptungen, sondern durch beweisbare, vernetzte Fakten.
Häufig gestellte Fragen (FAQ)
1. Was genau sind „Trust-Signale“ für eine KI?
Für eine KI sind Trust-Signale keine schönen Bilder oder Zertifikate, sondern Datenpunkte, die eine Behauptung validieren. Dazu gehören Verweise auf bekannte Entitäten (Personen, Organisationen), Zitate aus autoritativen Quellen (Studien, Fachartikel) und konsistente Informationen über verschiedene Plattformen hinweg.
2. Reicht E-E-A-T also nicht mehr aus?
E-E-A-T ist die Grundlage und für den menschlichen Nutzer weiterhin extrem wichtig. Für die maschinelle Verarbeitung ist es aber oft zu oberflächlich. Man kann E-E-A-T als die Benutzeroberfläche des Vertrauens betrachten, während strukturierte Trust-Signale das Backend sind, auf das KI-Systeme zugreifen.
3. Was ist der Unterschied zu einem normalen Schema-Markup für Autoren?
Normales Author-Schema deklariert, wer den Artikel geschrieben hat. Die von meiner Engine erzeugten Daten gehen tiefer: Sie identifizieren alle Experten und Quellen, die innerhalb des Artikels zitiert werden, und stellen deren Verbindungen zu Institutionen und Fachgebieten her. Es geht um die Beweiskraft des Inhalts, nicht nur um den Autor.
4. Warum ist das für Antwortmaschinen wie ChatGPT oder Perplexity so wichtig?
Diese Systeme wollen nicht nur eine Antwort geben, sondern die bestmögliche und glaubwürdigste. Wenn sie einen Inhalt verarbeiten, der seine Kernaussagen mit Verweisen auf anerkannte Experten und Studien untermauert, bewerten sie diesen Inhalt als vertrauenswürdiger. Solche Inhalte werden mit höherer Wahrscheinlichkeit als Quelle für generierte Antworten herangezogen.
5. Kann ich das auch manuell machen?
Theoretisch ja. Sie könnten jeden Artikel durchgehen, jede Erwähnung eines Experten heraussuchen, die entsprechende Entität in Wikidata finden und ein komplexes, verschachteltes Schema-Markup von Hand schreiben. In der Praxis ist das ab einem gewissen Umfang nicht mehr skalierbar und extrem fehleranfällig. Ein automatisiertes System ist hier der einzig praktikable Weg.
Fazit: Beweis statt Behauptung
Wir verlassen das Zeitalter, in dem es ausreichte, Autorität zu behaupten. Wir betreten eine Ära, in der wir sie maschinell beweisen müssen. KI-Systeme sind die neuen Gatekeeper des Wissens, und sie sind skeptisch. Sie glauben nicht, was auf einer „Über uns“-Seite steht – sie glauben, was die Summe der Datenpunkte im Web über Sie aussagt.
Die Zukunft der Sichtbarkeit gehört nicht denen, die am lautesten E-E-A-T rufen, sondern denen, deren Expertise und Vertrauenswürdigkeit in sauberen, vernetzten und validierten Daten vorliegen. Es ist an der Zeit, das Gold in unseren Texten zu heben und es den Maschinen zu zeigen.